







港聞更多

蟹樣本鎘含量和蠟油魚樣本甲基汞含量超出法例標準
食物環境衞生署食物安全中心(中心)今日(五月十四日)公布,一個蟹樣本和一個蠟油魚樣本分別被檢出金屬雜…




中國新聞更多

河南3歲男童被惡犬咬傷18天后不幸離世,男童母親發聲
來源:縱覽新聞 近日,河南3歲男童被狗咬傷不幸離世的消息令人唏噓不已。5月14日,縱覽新聞記者聯繫到…




焦點娛聞

aespaWINTER<Supernova>challengewithCHUNGHA【影片】
【Twi】aespa WINTER<Supernova>challenge with C…




體育報導

張之臻首進羅馬大師賽8強 下一輪將戰祖高域終結者
香港時間5月14日晚,在2024ATP1000羅馬大師賽男單第四輪比賽中,中國選手張之臻以2-0擊敗…




今日財經
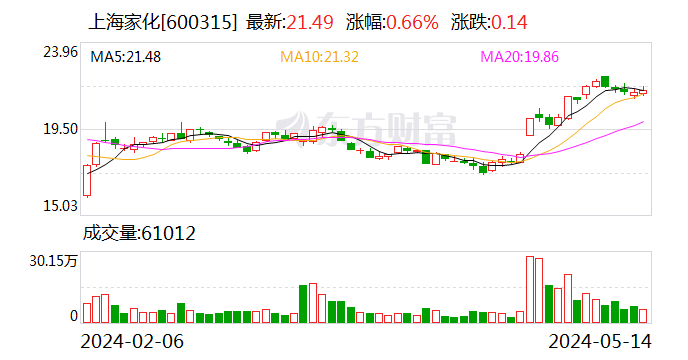
上海家化換帥:潘秋生辭任董事長 原高鑫零售CEO林小海接任總經理
不到四年,上海家化再次換帥。5月14日,上海家化聯合股份有限公司(上海家化,600315.SH)發佈…



熱門科技

看圖:阿里第四財季營收2218.74億元 2024財年已回購125億美元股份
阿里發佈2024財年第四財季財報:營收2218.74億元(淘天932億+國際數字商業274.48億+…



BEAUTY

梅麗爾·斯特里普亮相戛納photocall
#戛納紅毯#【#戛納明星造型# 】梅麗爾·斯特里普亮相戛納photocall,一身白西裝搭配法式禮貌…



生活消閒

秘魯酒店:【秘魯童話風奇形怪狀酒店 一覽迷人聖谷!鄰近古老奇觀馬拉斯鹽礦+莫瑞梯田!】-威法拉和諧飯店 Wifala Harmony Hotel
秘魯酒店2024|秘魯童話風奇形怪狀酒店 位於印加聖谷 鄰近馬拉斯鹽礦 莫瑞梯田 講起秘魯是一個人類…



