







港聞更多

蔡若蓮在馬耳他出席「學生能力國際評估計劃」會議
教育局局長蔡若蓮在馬耳他出席「學生能力國際評估計劃」PISA督導委員會會議,與其他地區的代表共同探討…




中國新聞更多

美媒:以軍或將因戰線過長力不從心
【美媒:#以軍或將因戰線過長力不從心#】美國《外交政策》雙月刊網站4月18日發表題為《以色列軍隊存在…



焦點娛聞

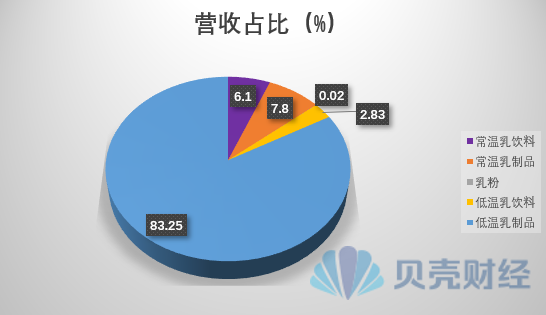
RIIZE×KakaoFriends,2024.04.23commingsoon
【Theqoo】RIIZE × Kakao Friends,2024.04.23 comming s…




體育報導

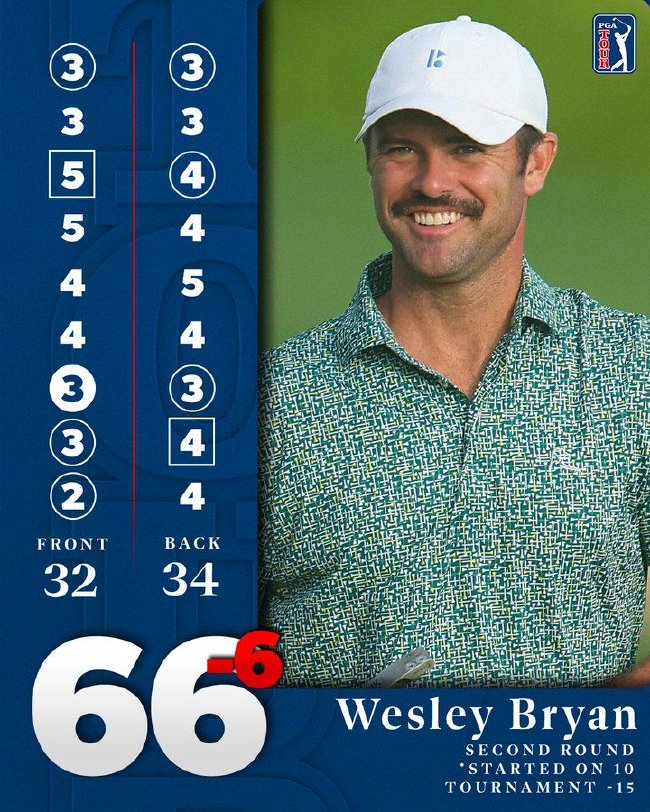
15歲羅素在光輝國際巡迴賽晉級 創造最小晉級紀錄
香港時間4月20日,美亞斯-羅素(Miles Russell)成為光輝國際巡迴賽創立35年以來最年輕…



今日財經

中國駐英國大使鄭澤光考察調研吉利倫敦電動汽車公司
中新網考文垂4月20日電 中國駐英國大使鄭澤光赴日前吉利倫敦電動汽車公司位於考文垂安斯蒂的工廠考察調…


熱門科技

迎接世園會,成都東部新區文旅行業吹響服務集結號
封面新聞記者 易弋力為迎接世園盛會,展現成都東部新區文旅形象,全力以赴構築文旅安全屏障和服務體系,使…



BEAUTY

LV2024早秋女裝系列大秀昨晚在上海龍美術館舉行
#沒十年功力玩不好LV大秀# LV 2024早秋女裝系列大秀昨晚在上海龍美術館舉行,品牌代言人及好友…




生活消閒

香港美食:【人氣街坊麵包店大推「壓扁牛角夾心餅」!共6款口味!抹茶/玄米茶/榛子焦糖朱古力】
香港美食2024|人氣街坊麵包店大推「壓扁牛角夾心餅」 本地街坊熱捧麵包店推出「壓扁牛角夾心餅」,不…



