







港聞更多
特區政府強烈不滿英官員就特區依法緝捕危害國安分子發表偏頗言論
原文刊登於 香港電台



中國新聞更多

哈佛大學宣佈關閉多元化辦公室
【#哈佛大學宣佈關閉多元化辦公室#】據埃菲社7月24日報導,一直與特朗普政府存在爭議的哈佛大學日前宣…




焦點娛聞

愛豆簽售會都在飯撒什麼【影片】
飯撒碳水的李沅禧,超萌奶黃包來襲! [xyz-ips snippet=”displayVideo”…




體育報導

跨越東西以球會友 共繪中西體育文化新畫卷
2025 年是中國與西班牙建立全面戰略夥伴關係 20 週年。值此重要節點,薩馬蘭奇體育發展基金會攜手…





今日財經

東江水供港六十周年──「識水思源」國家水利建設暨文化科技參訪團圓滿結束
由水務署、香港工程師學會及香港教育工作者聯會合辦的「識水思源」國家水利建設暨文化科技參訪團今日(七月…
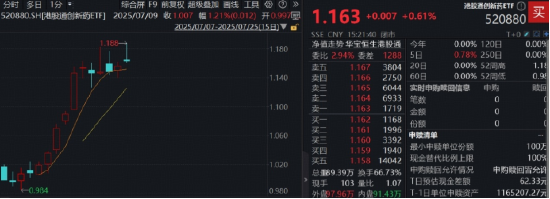
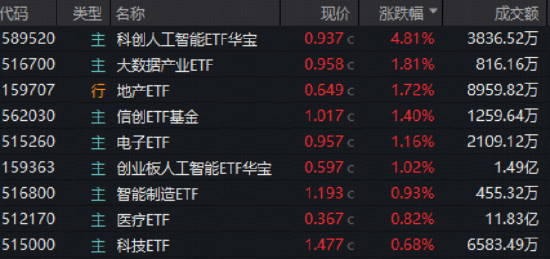
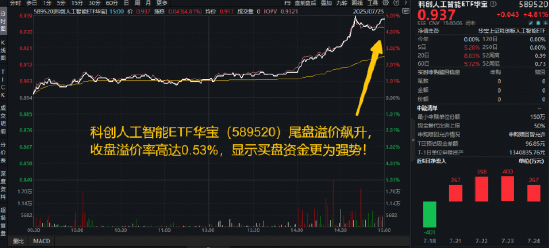
熱門科技

辛頓歷史性首訪中國,再次警告人類重視AI風險:AI就像一隻幼虎
7 月 26 號,2025 世界人工智能大會(WAIC)在上海正式開幕。這一次,我們迎來了 AI 領…


BEAUTY

Berluti推出Stellar運動鞋,延續KrisVanAssche在2019年呈現出第一款Stellar運動鞋
#尖貨指南# Berluti推出Stellar運動鞋,延續Kris Van Assche在2019年…




生活消閒

5個創意辦公空間設計,提升員工歸屬感及幸福感
對於每天待上至少8個小時的辦公空間,除了工作,更該讓人感到「安心存在」。 真正出色的辦公空間設計,不…



