







港聞更多
印度航空一架從香港飛往新德里客機降落後起火 無人傷亡
印度航空一個從香港飛往印度首都新德里的航班,在機場降落後起火,機上乘客和機組人員及時撤離,無人傷亡



中國新聞更多

尖叫品牌回應「紅色尖叫」炒到天價:臨期飲料不值得砸錢
新京報訊(記者王子揚)7月22日,「原價5元一瓶的紅色尖叫被炒到8900元一箱」登上社交平台熱搜。起…




焦點娛聞

真相猜‧情‧尋丨丁珮曾認與李小龍是孽緣 公開剖白無曖昧行為 不在乎外界…
真相猜‧情‧尋丨丁珮曾認與李小龍是孽緣 公開剖白無曖昧行為 不在乎外界…




體育報導

跌宕起伏!國安12碼大戰6-4戰勝青島西海岸進足協盃4強 侯森撲12碼
來源:香港時間 香港時間7月22日訊 香港時間19:00,足協盃8強青島西海岸vs北京國安,比賽在青…





今日財經

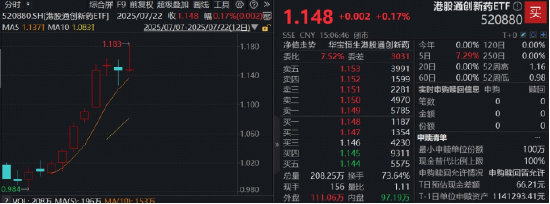
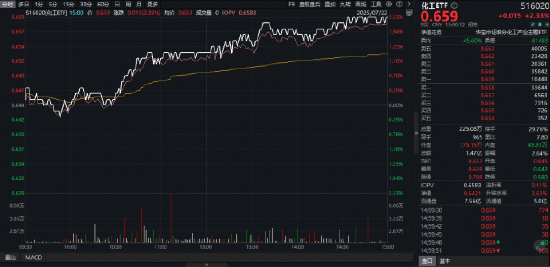
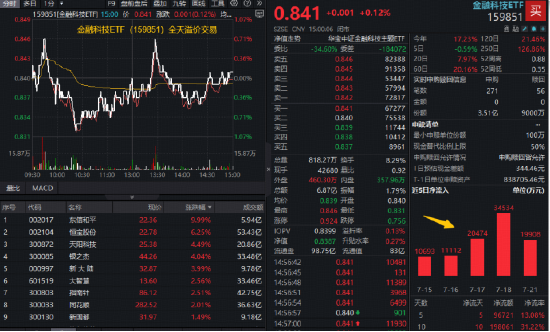
ETF日報:煤炭供給存在邊際收緊預期,需求隨迎峰度夏+非電用煤持續支撐,煤價反彈動力較強,可關注煤炭ETF
今日市場全天震盪走高,三大指數盤中均創年內新高。滬深兩市全天成交額1.89萬億,較上個交易日放量19…
熱門科技

699 元!小米偷偷上架這新品,看完我是真想買啊
小米百貨最近又又又上新了~沒錯,就是這款骨傳導耳機 2 !也就是第二代…話說之前果子用過一段時間…



BEAUTY





生活消閒

發惡夢原因|研究:睡前飲一物或增發惡夢機會 醫生建議食2物或可改善失眠問題
許多人習慣在睡前喝一杯熱牛奶助眠,但最新研究發現,這做法可能適得其反。台灣腦神經科學專家鄭淳予醫師引…



